




Industrial Data Mining in process industry
By N. Link and N. Holzknecht (www.bfi.de or on LinkedIn and ResearchGate)
The continuous improvement of production processes takes a major part of the daily work for those responsible for quality and production in process industry. Here, Data Mining (DM) technologies, as a part of Data Analytics (DA), have shown their usability and suitability in many published applications. Furthermore, many powerful DM tools are available, both commercial and open source applications.
In literature, often DM is mentioned as part of the Knowledge Discovery in Databases (KDD). The general aim is to detect relations between data, which are unknown or could not be derived from physical or technological models.
Originally coming from commercial applications, the application of Data Mining in process industry requires some more steps for the data handling. In the figure below a typical industrial DM process is shown.
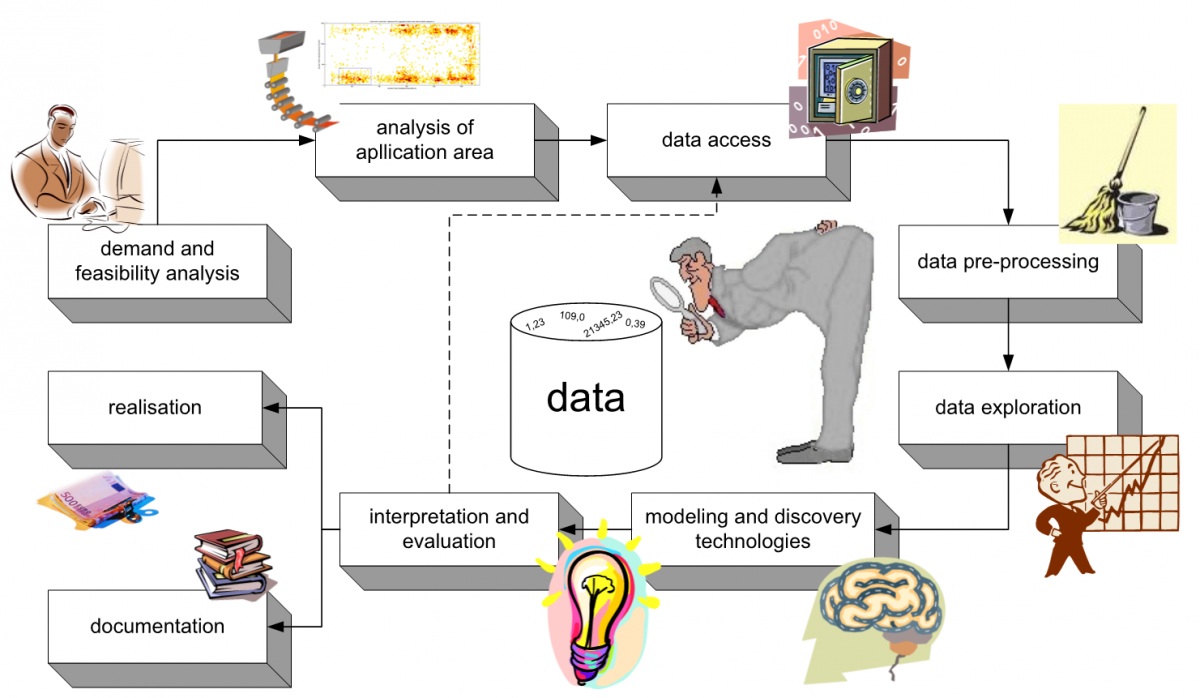
Data Mining itself refers only to the work steps described in the figure as "data exploration" and "application of modelling and discovery techniques". However, the user must always be aware of the origin of the data when using DM processes in the industrial environment. In this context, the areas "data access" and "data preparation" become such importance that they cannot be separated from the data mining process itself. The practical experience in the industrial environment of the process industry shows that these points often contribute more to the success or failure of a DM investigation than the applied "knowledge discovery" method. For this reason, "Industrial Data Mining" summarizes the steps of data access, data preparation, exploration and modelling and discovery techniques.
Due to their importance to the quality of the archived results, in COCOP the data presentation is subject of a separate task. The access to the data coming from different sources is important, especially when investigating a cross-process analysis. For the steel process, for example, the tracking of the material is necessary to be able to assign data length-related to the product. The product changes its geometry due to the forming processes as well as the top and bottom side or the beginning and the end due to the de-coiling and coiling of the strip.
Another topic is the pre-processing of the data. In an industrial environment, the data coming from automation systems or measurement devices have to be prepared to be usable for a DM analysis. Typical pre-processing steps are the detection and handling of missing or erroneous entries, smoothing and/or filtering of time signals or problem-adjusted standardisation and/or coding of input and output variables.
For the modelling of the processes necessary for global optimisation -that is the main aim of COCOP- data based models are also taken into account. Such models can be developed as regression models, estimating a continuous variable, or classification models, which deducts a discrete value representing a property of an estimated output. I.e. properties like "Surface Quality" will be described by classes, e.g. "Good", "Medium" or "Poor". For these modelling tasks a wide variety of methods are available like Artificial Neural Nets, Decision Trees, Genetic Algorithms and many statistical based approaches. Because such models have to be trained in an iterative procedure, one important part of data driven modelling is the generation of a suitable data samples. Such data samples, best one for training and one for validation of the developed model, have to represent the same data space and have to include the occurring different cases or situations in a balanced manner.
So, in Data Mining an important part of a successful development has to be done in the preparation of the data and the compilation of samples for the analysis and for the modelling.
Follow the discussion in the COCOP Debate Group of Linkedin

")
")
 (MSI)")
")

")
